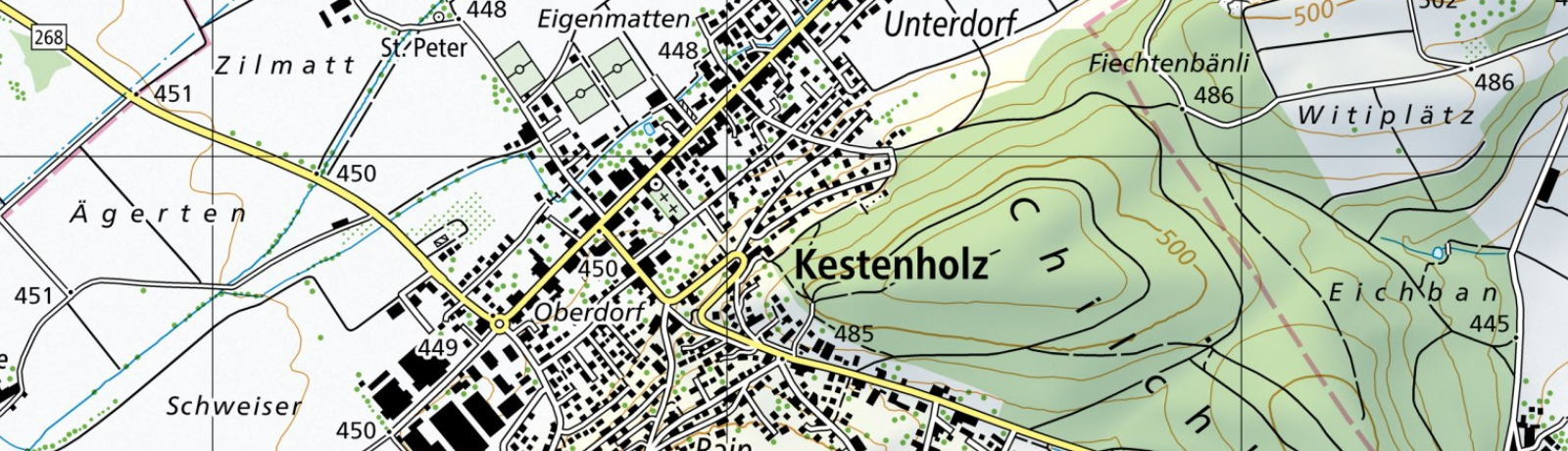
no route to host
Since some days I was struggling after an OLAM2 – Oracle Automation Manager 2.0 – setup, to connect to specific hosts. As you can see here in the picture, I was able to execute OLAM2 job templates (Ansible Playbooks) against a host in same subnet in 10.0.1.0/24, but not for the other one in subnet 10.0.2.0/24. The message was always the same: no route to host. But, in OCI basically each subnet has connection to the the other one, there is no special subnet routing withing a VCN Virtual Cloud Network. The setup on an OL8 machine was execute as described in the installation guide: Installation Guide (oracle.com). The setup type was Single Host.
For testing and debugging purpose, I have used a small playbook in a local defined project in folder /var/lib/awx/projects/pause. The gather_facts parameter ensures, that OLAM tries to connect to the target servers.
---
- hosts: all
gather_facts: yes
tasks:
- name: Pause for 100 minutes
ansible.builtin.pause:
minutes: 100
Test Run
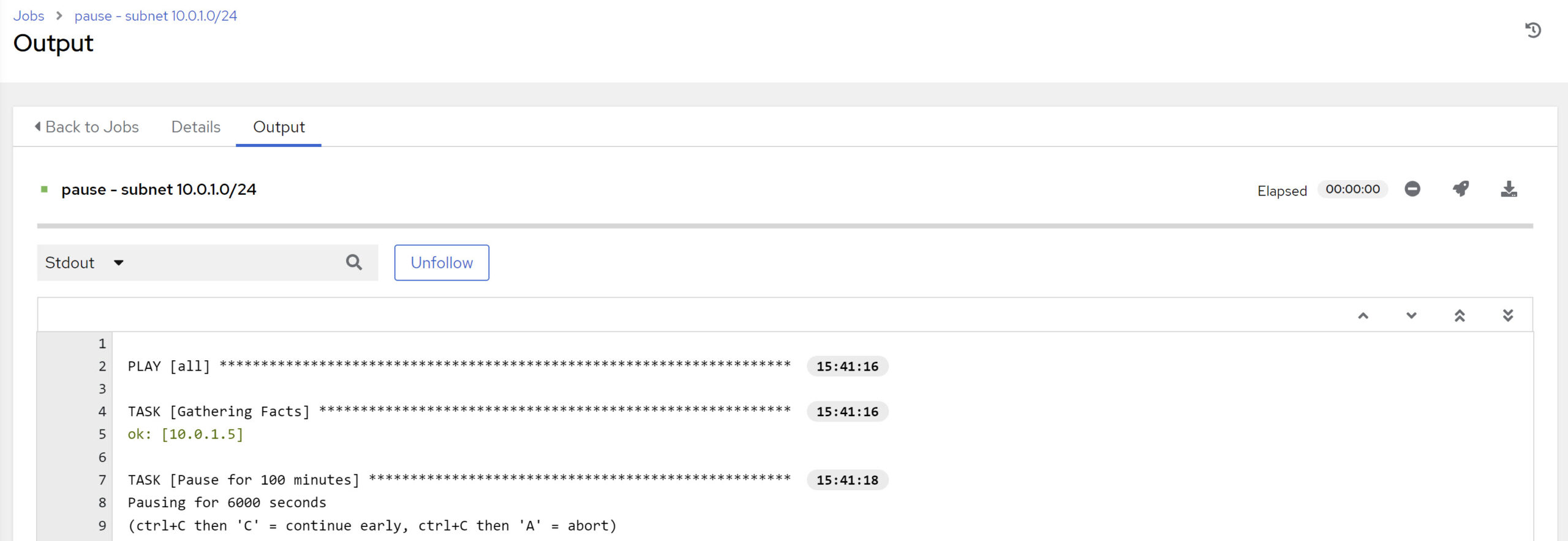
ci-linux-server-alpha – same subnet 10.0.1.0/24
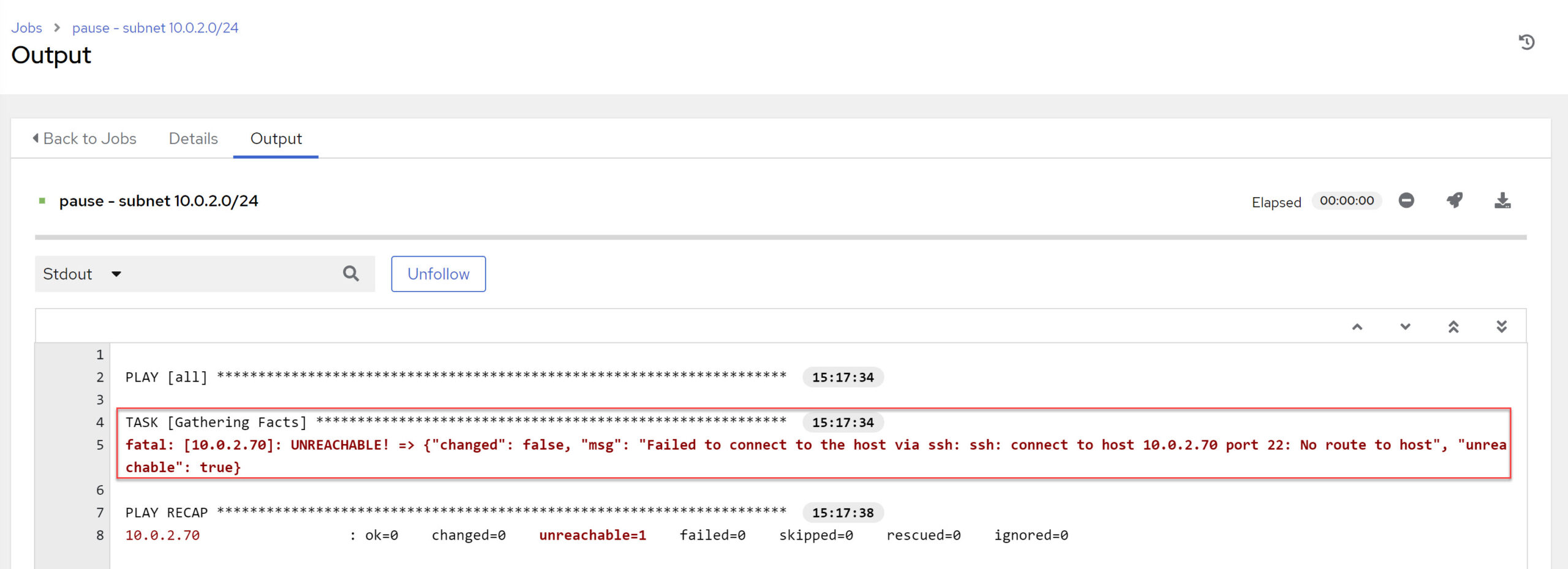
ci-linux-server-fox – other subnet 10.0.2.0/24
Connectivity
OS Host-to-Target Connectivity Check – OK
OLAM2 was not able to connect to the target server 10.0.2.70. Some short basics about OLAM2:
- In this setup, Tower, the repository database and the execution node are running on same host
- When a job template is executed, a Podman container is started in the back where the job runs
- The Podman configuration is “rootless”, this means OS user awx handled the container and all around
- To connect from container to external host, the Podman “bridge” mode for networking is set
Let’s check the SSH connectivity from OLAM2 host to target server to exclude OCI network firewall settings. This works.
[opc@ci-olam2 ~]$ ssh -i ~/.ssh/id_rsa_devops_2023 10.0.2.70 Activate the web console with: systemctl enable --now cockpit.socket Last login: Mon Feb 6 20:46:04 2023 from 192.168.1.45 [opc@ci-linux-server-fox ~]$ hostname ci-linux-server-fox
OS Container-to-Target Connectivity Check – NOT OK
Therefore, the Ansible playbook was adapted not to gather the instance statistics. In the background, a Podman container is started and running for 100 minutes.
---
- hosts: all
gather_facts: no
tasks:
- name: Pause for 100 minutes
ansible.builtin.pause:
minutes: 100
Job Template is running
Login into Podman Container
We get the ID to connect to the container and start Bash. As Podman runs “rootless”, we have to use the OS user awx. As you can see here, the OLAM-EE image is used for the container.
# sudo su -l awx -s /bin/bash $ podman ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES da61ceeb81c1 container-registry.oracle.com/oracle_linux_automation_manager/olam-ee:latest ssh-agent sh -c t... 5 minutes ago Up 5 minutes ago ansible_runner_24
Bash Connect to gather Container Network Information – no route to host
We verify the IP address settings of the container.
$ podman exec -it da61ceeb81c1 /bin/bash [root@da61ceeb81c1 project]#
[root@da61ceeb81c1 project]# ip address
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: tap0: <BROADCAST,UP,LOWER_UP> mtu 65520 qdisc fq_codel state UNKNOWN group default qlen 1000
link/ether aa:a4:28:f4:f8:13 brd ff:ff:ff:ff:ff:ff
inet 10.0.2.100/24 brd 10.0.2.255 scope global tap0
valid_lft forever preferred_lft forever
inet6 fd00::a8a4:28ff:fef4:f813/64 scope global dynamic mngtmpaddr
valid_lft 86308sec preferred_lft 14308sec
inet6 fe80::a8a4:28ff:fef4:f813/64 scope link
valid_lft forever preferred_lft forever
[root@da61ceeb81c1 project]# ip route
default via 10.0.2.2 dev tap0
10.0.2.0/24 dev tap0 proto kernel scope link src 10.0.2.100
SSH fails – no route to host
[root@da61ceeb81c1 project]# ssh 10.0.2.70 ssh: connect to host 10.0.2.70 port 22: No route to host
Here we are – no route to host. The facts:
- SSH from OLAM host to target works
- SSH from Podman container to target fails
- OCI networking can be excluded
Network Subnet Comparison – 10.0.2.100?
I was wondering, where the IP address 10.0.2.100 was coming from. This IP is from the same network range than the OCI compute instance ci-linux-server-fox is coming from (10.0.2.0/24). But where does it come from? After some research in the www, I found the answer in the method, how Podman is used: “rootless”. From the podman-run — Podman documentation:
slirp4netns[:OPTIONS,…]: use slirp4netns(1) to create a user network stack. This is the default for rootless containers. It is possible to specify these additional options, they can also be set with network_cmd_options in containers.conf:
- allow_host_loopback=true|false: Allow slirp4netns to reach the host loopback IP (default is 10.0.2.2 or the second IP from slirp4netns cidr subnet when changed, see the cidr option below). The default is false.
- mtu=MTU: Specify the MTU to use for this network. (Default is
65520). - cidr=CIDR: Specify ip range to use for this network. (Default is
10.0.2.0/24).
Looks like Podman shares by slirpnet4netns the same IP address range that I use in Oracle Cloud Infrastructure…
Oracle Cloud Infrastructure Test with Subnet 10.0.3.0/24
For another test, a new subnet with range 10.0.3.0/24 is created and a new machine is running: ci-linux-server-golf with IP 10.0.3.87. Let’s see what happens there when we add this host to OLAM and enable information gathering in the Ansible playbook again. Tataaaaaa – the job template is running fine!

Solution & Summary
Take care when running OLAM2 that internally subnet range 10.0.2.0/24 is used. If the same subnet is available in OCI, we have a conflict. As workaround: DO NOT USE 10.0.2.0/24 for a target server subnet. And now I have to watch into the slirp4netns documentation – let’s see if there is a change to change the internal used CIDR in “rootless” mode. #networkfun #research